Diving into Branch Rickey: Using a dataset of crowdsourced transcriptions as a tool for open research
Today’s blog post is from Abby Shelton and Lauren Seroka, two Digital Collections Specialists in the Digital Content Management Section here at the Library of Congress. Abby and Lauren discuss their work with the University of Michigan School of Information’s Ann Arbor Data Dive earlier this year.
On March 27, 1956, Branch Rickey wrote of baseball player Joe Trimble, “This young right hander has major league stuff. When he really cuts loose on his curve ball, it is unhittable.” Sixty-five years later, on March 27, 2021, students from the University of Michigan’s School of Information and Ann Arbor community members met online to see what they could make of Rickey’s scouting reports. And their findings were some “major league stuff”!
After By the People volunteers finished transcribing 1,926 pages of Rickey’s reports, LC Labs created a dataset from the crowdsourced transcriptions which you can read all about in one of our previous Signal posts. While the completed transcription data appears on each page to allow for full-text searching on the Library’ website, the datasets allow users to analyze the transcriptions in bulk. By the People intends to turn all of its completed campaigns into datasets and so far we’ve published sets from the Branch Rickey, Carrie Chapman Catt, William Oland Bourne, and Samuel J. Gibson papers. We’re excited to hear more from our community about how folks are using these to explore new avenues of research, answer new questions, and test out their data processing skills.
In March, the A2 Data Dive team invited By the People to contribute its Branch Rickey dataset to their annual hack-a-thon event. Every year, the A2 board connects a set of non-profits with University of Michigan students and interested community members to both provide data analysis for non-profits and to help data enthusiasts to build their skills. This year, we gathered on Zoom with over fifty participants for an eight-hour day of data processing!
The day began with a quick kick-off meeting where By the People team members Abby Shelton and Lauren Seroka introduced the Rickey dataset alongside the other participating non-profits – Saide African Storybook and Democracy Ballot Scout. After the kick-off, participants chose a project team and began exploring one of the three datasets. The Branch Rickey team split into two sub-groups and started work on date and sentiment analysis.
The Branch Rickey datasets presents some inherent challenges to users in that it’s largely natural language data in the form of crowdsourced transcriptions. The dataset contains a few standardized columns (including campaign and project titles) and status flags to indicate that the page has been digitized and transcribed. But the the substance of the data is completely free-text. Before any meaningful analysis could begin, Data Dive participants had to explore the data itself to get a sense for the content and whether they could discern any useful patterns within the data.
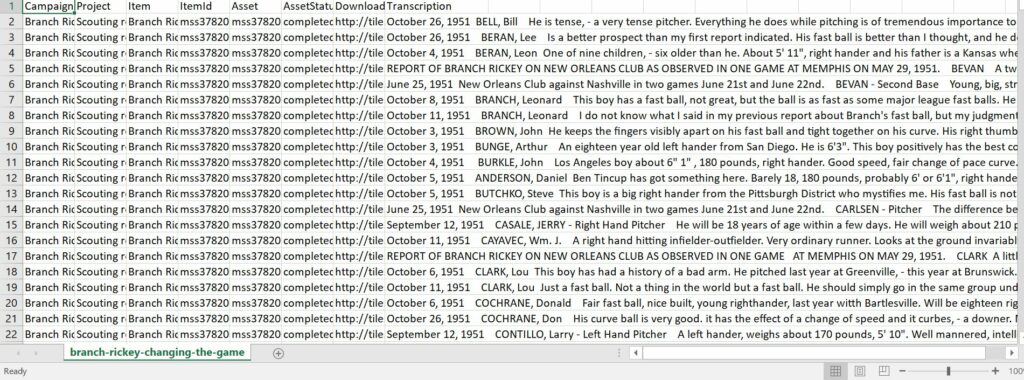
Close-up of portion of the Rickey dataset showing columns titled Campaign, Project, Item, ItemID, Asset, AssetStatus, Download, and Transcription data.
The first group began by attempting to pull dates out of the transcriptions and quickly found they needed to spend a lot of time on data cleaning. For instance, they need to figure out a way to make sure to prevent height and weight data from being converted into dates. Some of the first questions they needed to resolve from the data included:
- How best to reduce inaccurate capturing of dates?
- How to convert string dates into date objects?
- How to extract dates and months from the date objects?
Many of the scouting reports include data information recorded as Month, Day, Year at the beginning of the report, but Rickey did not follow this formatting scheme consistently as seen in the images below. Sometimes, the report title proceeded the date information or Rickey would include the day of the week in his date string. And occasionally, Rickey failed to include a date at all so the team had to decide what to do with undated transcriptions.
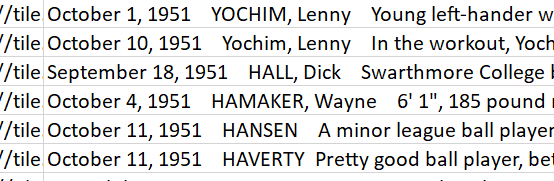
Close-up of Rickey dataset showing the Month, Day, Year date format.
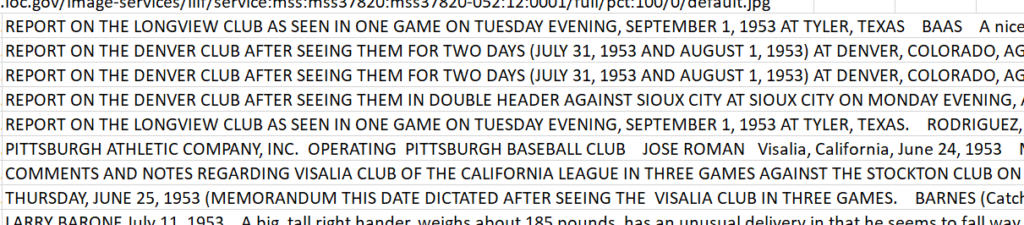
Close-up of Rickey dataset showing instances where the Report title precedes the date and where Rickey inserted the day of the week into the date.
Using a combination of regular expressions, a datetime library, and lamda functions, the team was able to identify some patterns in the data. They determined that the majority of the reports date to 1963 and, in 1963, Rickey wrote most of his reports in in the month of July. The same was true for other years-Rickey dated most of the reports between March and July. This fits with the pattern of the usual baseball season in the 1960s, which ran from April to October. Rickey scouted players on minor and other major league teams, college teams, and local leagues.
The second team took a difference approach to the data-performing sentiment analysis on the reports to determine how many of the reports were positive versus negative. They also examined how Rickey’s sentiments may have changed over time. And in particular, they looked at the reports that Rickey wrote about pitchers.
They used the DistilBERT model-a code package that can be used for natural language processing-to determine whether reports trended positive or negative. The team found for the earlier portion of the collection (before 1954), Rickey’s reports tended 56% positive whereas that dropped to 50% after 1960. Reports written after 1960 tended to be 14% longer but Rickey used shorter words to describe the players he observed.
The team found that Rickey could be a lively observer and often recorded details not only about the player’s ability but about their family life and background as well including details about their appearance. For example, Rickey described one player as “This boy has what I would call fine hitting form and a lot of power. Right hand thrower, left hand hitter, and has all the manner and appearance of a splendid gentleman.”

Rickey’s scouting report for Henry Fisher from September 18, 1951.
On the background of one athlete, Rickey said “One of nine children, – six older than he. About 5′ 11″, right hander and his father is a Kansas wheat farmer. He really lives on a farm.”

Rickey’s scouting report for Leon Beran dated October 4, 1951.
And when Rickey dismissed a player’s ability he often did so in harsh terms. Rickey wrote of one player in 1962, “Bell is a scarey-cat[sic], — knows nothing about pitching, and knows he knows nothing. Has no confidence in himself and is highly receptive to advice. He has big ears.”

Rickey’s report for Bill Bell dated October 1, 1951.
We appreciate the time and effort that both teams put into exploring the Rickey dataset as processing free-form transcriptions is no small task! The teams also had great ideas for future research – for instance, pulling names from the reports and comparing with other published baseball datasets – and we hope someone will pick up those queries in the future. Publishing transcription-based datasets is a new initiative for By the People and we’re curious to see how folks will take, transform, and use our bulk data.
If you’ve explored our datasets and have some findings to share, we’d love to hear about it! Contact us here or leave us a comment below!
Source of Article