Next Slide Please: 2021 Digital Strategy Summer Intern Design Sprint part I

This summer, the Digital Strategy Directorate, home to LC Labs, hosted seven interns working on projects to broaden the reach and potential impact of our initiatives.
This is the first of two interviews with the 2021 summer cohort discussing a group activity they undertook in teams. In this post, I sit down with Emily Zerrenner, Jodanna Domond, Luke Borland, and Darshni Patel. About halfway through their internships, they paused their individual projects and worked as a small group to better understand the Library’s Web Archives with the needs of researchers and data visualization artists in mind.
Can you tell our readers more about your group activity? What was the assignment?
For five non-consecutive days of our summer internships, Digital Strategy Directorate interns worked together in teams to make a dataset useful to a target audience of our choice. Along the way, we learned about key concepts of user-centered design and data transformation. The activity was called a “design sprint”, which meant we had to make decisions quickly and later return to them in order to check our assumptions. Our focus was less on the final product and more about the process – what was it like working with the dataset? What kinds of needs could we anticipate from the user?
How did you approach the design sprint as a group? What dataset did you work with?
After a lot of deliberation, we came together as a team (we named ourselves ‘Digivision’) and decided to use Web Archives Derivative datasets. These media files included files from tabular, pdf, audio, image and PowerPoints archived from websites ending in .gov.
We decided to use a derivative dataset of 1000 PowerPoints because we were interested in the amount of rich textual and visual information contained in them. We knew this might be harder to work with, both intellectually and literally; there was a lot of background information to understand about web archives. As a derivative dataset the archiving team made a series of decisions to create the dataset before we began working with it. Uncovering the background information helped us to understand the impact of the choices. Because it was a random sampling, the content of each PowerPoint was quite unrelated, and difficult to imagine why a specific user group might want to search information captured in the PowerPoint medium. Nevertheless, we found great interest in the possibilities of these Web Archive datasets, so we pushed forward.
-

- Emily Zerrenner
-
- Darshni Patel

-
- Luke Borland

-
- Jodanna Domond

What were some of those challenges you encountered while working with this dataset?
There were quite a few blockers that hindered the use of the dataset. The dataset comes in at about 3.6 GB, which is a big download for anyone. Our team had trouble, to the point where most of us couldn’t download the dataset and view its contents at all. It is difficult and time consuming to browse through the files as they are currently, and as we discovered in our user interview, many people aren’t aware of this resource.
With these considerations in mind, we came up with our core problem to solve: how can we make a product that is easy to navigate without having to download each file, and in turn, make this dataset more accessible?
Fascinating to hear how this activity encouraged you to really experience firsthand the complexities of working with large datasets. How did your proposed design solve that problem?
The conceptual solution we settled on was to create a searchable database for these 1,000 PowerPoints. It would give background and context to the dataset, and give users the opportunity to group the files by date, geography, topic, and many others. The first iteration of our prototype, shown here, includes a search box with the ability to search by publishing website, keyword, etc. On the homepage, it shows the user a random PowerPoint from the collection. At the bottom, we imagined ways to browse them via data visualizations – so by color, how many times the presentation was revised, and others.
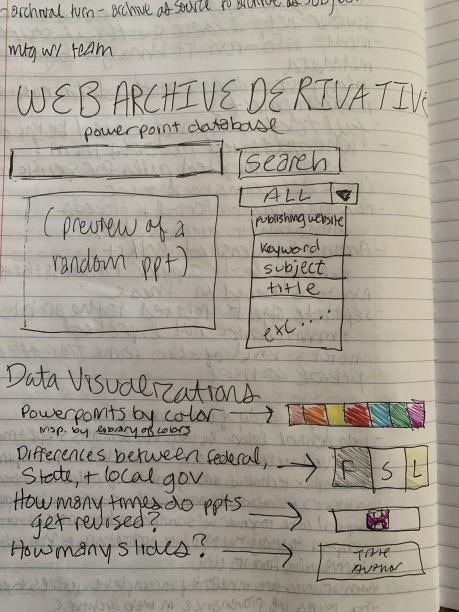
Our final “pen and paper” prototype attempts to meet the needs of two different categories of audiences identified: novices and advanced researchers. We did this by creating two landing pages that are responsive to the specific needs of both of these groups, which are described below.
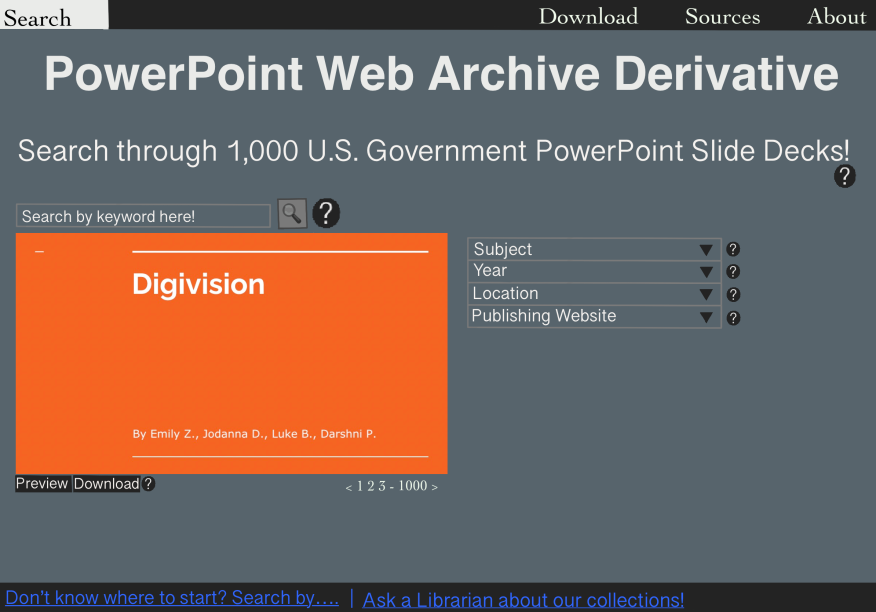
We made the researcher page more dependent on the user for search inquiries that expose a narrow set of data.
On the other hand, we wanted to have another, friendlier entry point that allowed for broader, open exploration.
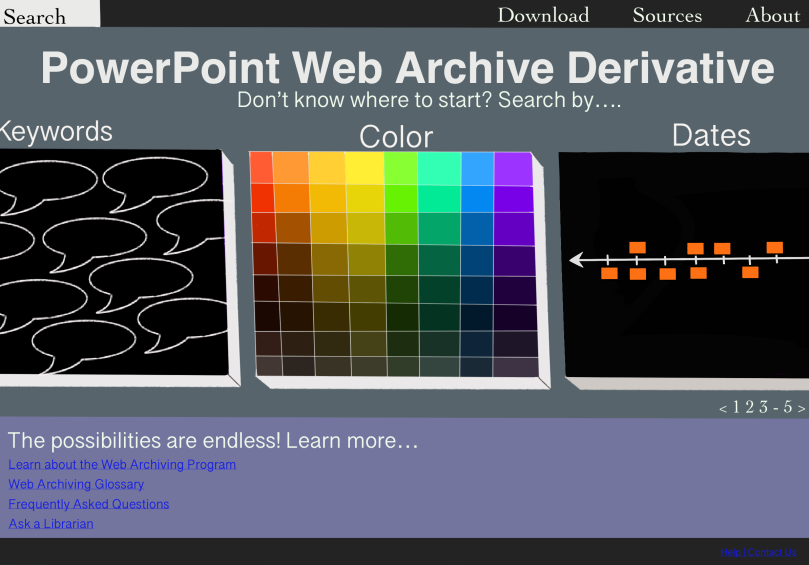
Our thinking was that researchers may be asking more targeted questions that may help them find their specified document whereas novices would enjoy interactive ways of searching that may spark curiosity and provide multiple routes to searching.
Moreover, the novice page has an imaginary ‘learning guide’ linked at the bottom to help them better explore/understand the data set. These sorts of adjustments remedied perceived tensions between the needs of the divergent user groups and incorporated feedback from an interview we did with two hypothetical users.
Oh interesting! Can you say more about this imagined possible user of the dataset?
After some brainstorming, we came up with three potential user bases with a spread of novice and advanced technical skills: researchers, undergraduate students, and data visualization artists.
Researchers could use this dataset to understand practices of government agencies’ communications with the public. Undergraduate students could use the dataset to practice digital skills and learn how to explore information through creating visualizations or using the dataset to create a searchable database. Finally, data visualization artists may find PowerPoints a useful tool to illustrate trends in government communications, how PowerPoints have changed over time, or any number of other topics, such as accessibility through color usage, screen reader compatibility, and font choices.
We imagined this dataset could be used not only to research topics in our user groups’ fields of study, but also to help them gain general experience in working with data. As a derivative dataset, the PowerPoint data offered users a glimpse of information available but also narrowed its scholarly usefulness.
As part of the activity, we were able to interview two professional software and data librarians. We did this in the earlier design phases so we could be sure to incorporate their feedback into our final prototype. Their suggestions and feedback were vital for our final prototype; they suggested to still give the option of downloading the entire dataset for those with interest in high performance computing, while also giving the option to preview and browse through any PowerPoint without the need to download it for those with limited computer storage. They also suggested having a cohesive landing page, with links to applicable resources, the Library’s Ask A Librarian service, and any other relevant information about the dataset.
Thank you so much for sharing about your thinking and process! Did you learn anything else from the design sprint?
As a team, we did extensive background research on web archives in general to get a better grasp on these datasets and where they came from. The learning curve was steep, but the speed of the design sprint itself allowed us to get past this research and analysis phase – despite feeling not quite comfortable with the dataset – to come up with a prototype. We had come across some of these datasets before in our onboarding and research, but the opportunity to think deeply and stretch our brains in ways we hadn’t before was invaluable.
As remote workers from all over the country, this design sprint was also a great way to connect us and get us working with Library of Congress materials. In lieu of an in-person experience, this was a useful exercise in getting interns from across the department working and learning together!
Source of Article