Newspaper Navigator Search Application Now Live!
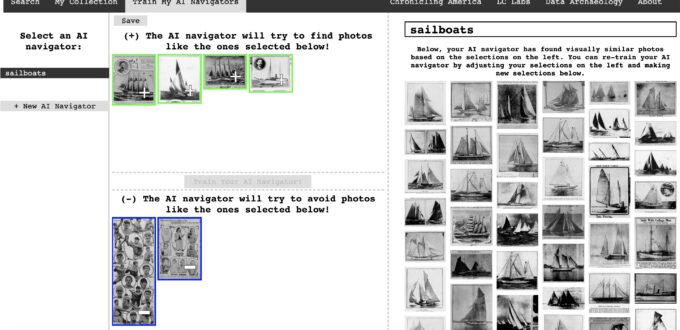
On September 15, 2020, the Library of Congress announced the release of Newspaper Navigator, an experimental web application which allows members of the public to visually browse 1.5 million photographs from Chronicling America using machine learning. Read more about the design and features of the project below or jump straight to the newly launched application at //news-navigator.labs.loc.gov/search !
About Newspaper Navigator
For nearly two decades, the Library of Congress has worked with partners across the United States to digitize America’s historic newspapers. Putting together the resulting 16 million newspaper pages (and counting) in the Chronicling America database made them easily searchable by text. But the newspapers also contain millions of images—photographs, illustrations, maps, comics, advertisements, and more. In 2019, Library of Congress Innovator in Residence Benjamin Lee set out to find all of those images and make them just as easily searchable, through the power of machine learning. In May 2020, the Library released millions of these images as downloadable data sets and showcased this debut with a public data jam.
Lee created Newspaper Navigator by training a computer algorithm to recognize and extract images from text using a machine learning method. As a result, he was able to cull one of the largest sets of images from historic newspapers in the world, now available to the public at no charge. But in addition to the sheer volume of images he extracted, Lee also used machine learning to revolutionize the ways users can search them.
Using the application, visitors can search over the million images using a keyword, browse the thousands of images returned, and select relevant photos to train the algorithm to identify similar images based on their content, refine, and search again. For example, a visitor can begin by searching on the word “sailboats”, and Newspaper Navigator will find any image which appears alongside the word “sailboats” in the newspapers. As the visitor reviews the gallery of returned images, she decides she only wants to see pictures of sailboats, so she selects some example photographs of sailboats to add to her training library, and performs the search again.
This is where the exploratory nature of the tool features prominently, because the machine learning algorithm will scan across over a million photographs in seconds, returning images of sailboats even if the word “sailboats” appeared nowhere in the text associated with the returned images. In this way, the Newspaper Navigator algorithm developed by Lee uses “input” images selected by visitors to train a machine learning algorithm “on the fly” to identify visually similar images. While companies like Google have developed image searching techniques, Newspaper Navigator directly empowers the site’s users to train a machine learner to search over a million images. It is the first such tool developed by a not-for-profit organization for use with cultural heritage materials.
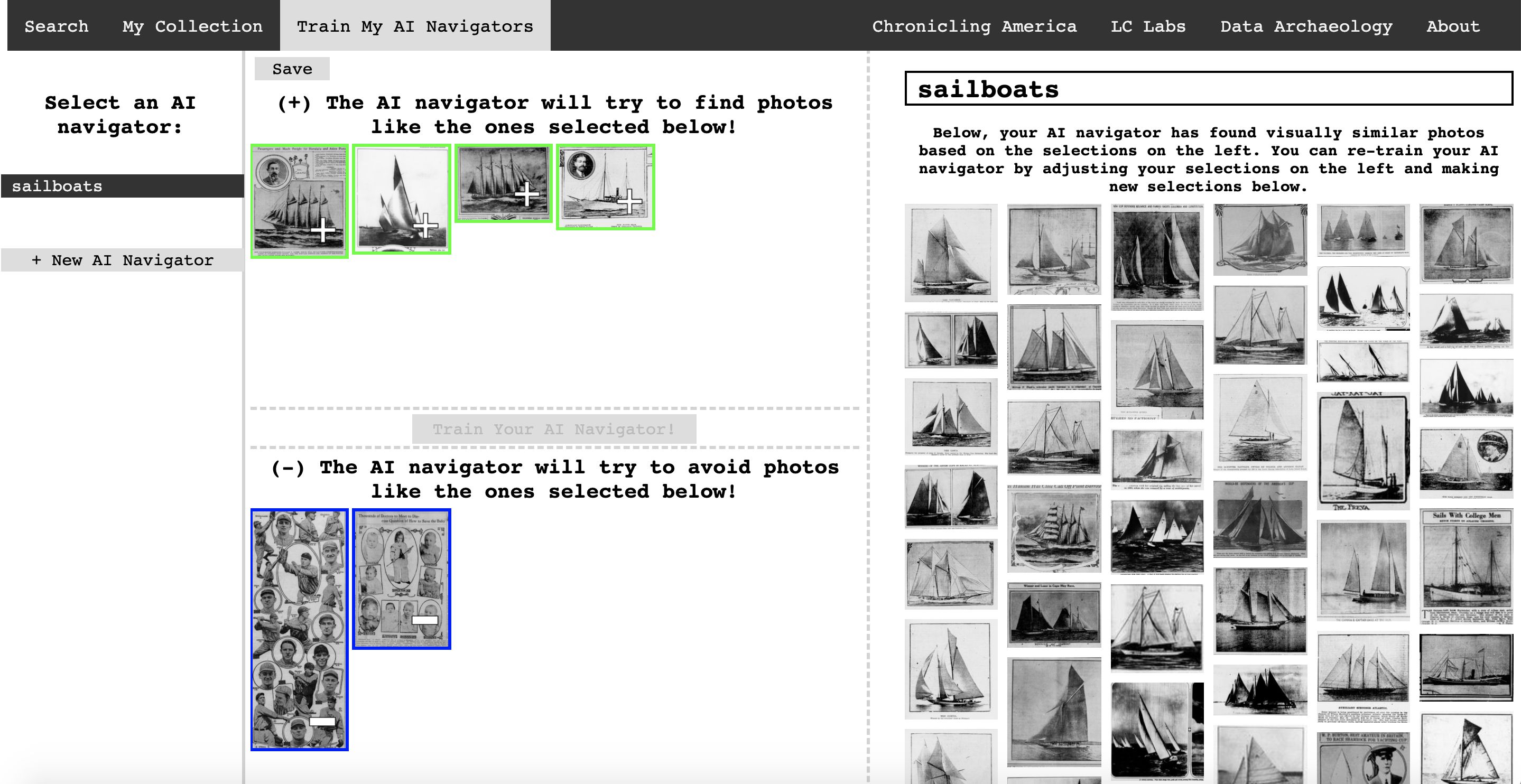
A screenshot of a refined search for images of “sailboats”
About the newspapers
The 1.5 million+ public domain photos in the Newspaper Navigator dataset are an incredible boon for anyone interested in American history. Created and maintained by the National Digital Newspaper Program, a partnership between the Library of Congress and the National Endowment for the Humanities, Chronicling America is one of the largest free databases of digitized historic newspapers in the world. The growing database includes over 16 million newspaper pages published across the country from 1789 to 1963, many of them small, local newspapers that document everyday life and world events through centuries of American history. With the existing Chronicling America search portal, visitors can search across the millions of pages of newspapers in the database by keyword and other metadata fields, read the original documents in a digital format, and learn more about the newspaper titles. Historians, genealogists, teachers, students, and curious members of the American public regularly use Chronicling America to explore our collective history as well as their own families and homes.
Full text searching is essential for making Chronicling America’s news stories accessible—anyone can search for family names, hometowns, the price of a good shave, and even media coverage of pandemics such as the Spanish flu. However, the Library needed further innovation to make the rich visual content of the newspapers just as available. Photographs, cartoons, maps, and illustrations are ubiquitous in historic newspapers and are portals back in time, and their visual characteristics often convey information beyond what accompanies them as text in the form of captions and titles. Text searching is made even more difficult by changing terminologies, inaccuracies in Optical Character Recognition, and the dozens of languages now represented in the newspapers. Allowing researchers to move beyond textual keyword searching allows new and exciting windows into phenomena as far ranging as the ways fashion trends changed over the years to how fans of America’s pastime would have seen the baseball stars of a century ago. Finding images on their visual characteristics allows historians, students, genealogists, and others more complete access than ever before to one of the most important historic records of daily life in the United States.
History of the project(s)
Although Lee was able to create Newspaper Navigator and its larger companion dataset of images within the year of his residency at the Library, the project builds on 20 years of effort to both manually and automatically describe these pages in ways a computer can understand. As the Library began working with the NEH and states around the country to select, digitize, and mail USBs and hard drives to the Library in the early 2000s, a schema called METS-ALTO had to be developed for describing the layout of each page down to the pixel. From there, the Library began making the newspapers publicly available through an online search portal, publishing the newspapers as bulk data downloads with full text, and created an API (application programming interface) for programmatic use.
“The most significant aspect of Newspaper Navigator is that it’s the product of decades of effort,” said Kate Zwaard, Director of Digital Strategy. “It’s just that the technology finally caught up to the richness of the data. We are at a critical time for libraries for experimenting with the ways members of the public can engage with the materials we make available online.”
In 2017, Library of Congress Labs, a small team within Digital Strategy Directorate that runs experiments and pilots to test emerging technologies with the Library’s collections, used the newspapers in the crowdsourcing experiment Beyond Words. Website visitors were asked to help identify cartoons, illustrations, photographs, and advertisements in a subset of WWI-era newspapers. Visitors drew boxes around any visual content on a single digitized newspaper page, and could transcribe or review other users’ transcriptions of the captions accompanying each image. When Ben Lee came across this project, he was in the first year of his computer science doctoral program, and recognized an opportunity to build on the work of these volunteers to create a training dataset for a machine learning algorithm that might work on the entire Chronicling America corpus. “When I first encountered Beyond Words, I was captivated by the thousands of photographs, illustrations, cartoons, and maps identified by volunteers. I began to wonder whether this identified visual content was the key to throwing open the treasure chest of visual content throughout all 16 million pages in Chronicling America using machine learning,” said Lee. He applied to the Library’s annual Innovator in Residence Program to try it out.
“Ben’s proposal was impressive because it was so technically ambitious. We knew that it would be the first time the Library had developed a machine learning application in-house and we wanted to see if we could do it,” said Jaime Mears, a member of LC Labs who leads the Innovator in Residence Program. “There was also a commitment to transparency in his proposal, to expose along the way how mediated and flawed machine learning actually can be.”
Documenting the shortcomings of the technology
Lee’s work fits with LC Labs’s ongoing commitment to transparency and ethics, especially consideration for the human time, labor, and expertise involved in creating the datasets used for training machine learning algorithms. As Lee began his residency in September 2019, he attended the LC Labs-hosted Machine Learning + Libraries Summit. The conference emphasized the need for the Library of Congress to continue investigating the social and ethical concerns of machine learning alongside its technical or practical applications.[1]
Lee’s project also intersected with another exploratory demonstration project LC Labs was undertaking at the time with the Project Aida team at the University of Nebraska Lincoln. Drs. Liz Lorang and Leen-Kiat Soh worked with Ph.D. candidates Yi Liu and Chulwoo Pack to test out no fewer than five possible applications of machine learning for Library of Congress’s digital collections. They also used data from Chronicling America to test the possibility of Document Segmentation, or segmenting image and text material from newspaper content; Figure/Graph Extraction, or finding figures in newspaper content and extracting text from figures; Document Type Classification, or classifying handwritten vs. typed material; Quality Assessment, also known as analyzing image quality of digitized MSS material; and Digitization type differentiation, or recognizing image digitized from microfilm.
Lee had already demonstrated a particularly careful approach to the use of automated methods to process and make discoverable sensitive cultural material. During his time as a Digital Humanities Associate Fellow at the United States Holocaust Memorial Museum, he worked with the International Tracing Service archive to improve access to its digital materials. The archive is one of the world’s largest repositories of documentation pertaining to victims of the Holocaust, including his own grandmother, a survivor of Auschwitz-Birkenau Concentration Camp. “My own experiences of navigating cultural heritage collections in pursuit of my family’s history have had a profound impact on me, both at a personal level and in relation to my research. Improving access to digitized collections has become the driving force behind my research, including Newspaper Navigator. Moreover, through my personal experiences, I’ve come to appreciate the sensitivity that the cultural heritage collections necessitate. With my work, it’s especially important to me that I apply machine learning techniques ethically, responsibly, and with care.”
For the Newspaper Navigator project, Lee is particularly committed to documenting the history of the data itself. This is especially critical for projects that leverage machine learning technologies because these algorithms learn to detect patterns based on the data they’re presented. So if, for example, a majority of people are light-skinned in historic images, the algorithm would grow better at detecting lighter-skinned people in new images introduced to the system to the detriment of darker-skinned people in the images. In order to study these effects – known as algorithmic bias – as they relate to Newspaper Navigator, Ben has written a paper called a “data archaeology.” In the paper, Lee studied four different newspaper pages reproducing the same image of W.E.B. Du Bois as the pages travel through Chronicling America and Newspaper Navigator. He uncovered that because the microfilming process distorts the skin tones of darker-skinned people in photos, the machine learning algorithm used for discovery in the Newspaper Navigator search interface was unable to identify all four images of W.E.B. Du Bois as related. He has provided this case study as part of Newspaper Navigator to educate users of the dataset and interface about algorithmic bias and the ways in which machine learning can perpetuate marginalization.

The same image of W.E.B. Du Bois reproduced in 4 different digitized Black newspapers in Chronicling Americafrom 1910. Note that the combined effects of printing, microfilming, and digitizing have led to different visual effects in each image, ranging from contrast to sharpness.
Indeed, machine learning is being used to power many of our current tools – from banking to social media – but it often is employed invisibly behind the interface. Newspaper Navigator is significant for its transparency. By allowing users the ability to train an algorithm on the fly, they can learn intuitively in real time how their tweaks affect the results and can see where the tool quickly reaches its limit. For example, the algorithm has a difficult time distinguishing between similar shapes such as a horse and a dog. And yet, because it provides a way for researchers to search beyond the captions of a photograph, there’s a powerful potential for how these newspapers might now be used.
What’s next?
Jim Casey, an assistant professor of African American Studies at Penn State, has already identified ways Newspaper Navigator will assist researchers. “As I am writing a history of editors in the early United States, Newspaper Navigator will be an invaluable tool for charting the visual culture of the press. It provides us with a wealth of clues about the work of editors (behind the scenes) to forge the look and feel of the first drafts of history.” Casey added, “Ben Lee’s work at the LC Labs is a first-rate example of how computing can help us understand our cultural heritages in new and unexpected ways. I expect that the Newspaper Navigator platform is going to open up many new areas of research because it allows us to ask new kinds of questions. Beyond just keyword searches, we can now begin to explore the patterns and eccentricities of visual culture of newspapers across millions of pages. It’s like sonar for Chronicling America.”
“Newspaper Navigator affords a whole new dimension of access to Chronicling America,” said Molly O’Hagan Hardy of the National Endowment for the Humanities, the Library’s longtime partner in the National Digital Newspaper Program, which produces Chronicling America. “Images and words on the printed newspaper page interact to construct meaning for readers past and present, and we miss half of that meaning making when our searches rely exclusively on the written text.” Hardy added, “Newspaper Navigator allows us to access and therefore to understand historical newspapers in hitherto unprecedented ways, and we are so eager to see the exciting discoveries it will enable in Chronicling America.”
Lee finishes his Residency in September, but Newspaper Navigator represents the beginning of Lee’s dissertation research at the University of Washington with his advisor, Professor Daniel Weld. As Lee explains, “I’m particularly excited about the new mode of search included in the Newspaper Navigator web application, which opens the door to many possibilities for studying not only exploratory search but also human-AI interaction. I look forward to continuing to study and refine this search method as part of my dissertation.”
All code for Newspaper Navigator, including the code for the dataset construction and for the web application, is open source and placed in the public domain for unrestricted re-use. Both sets of code are available at https://github.com/LibraryOfCongress/newspaper-navigator. The Library encourages others to re-use this code for their own projects related to historic newspapers and beyond.
To share any photos that you’ve found using Newspaper Navigator, tweet @LC_Labs with the hashtag #NewspaperNavigator!
[1] See the “Machine Learning + Libraries Summit Event Summary” report for a full outline of emerging trends and key recommendations.
[2] See the “Digital Libraries, Intelligent Data Analytics, and Augmented Description” report for more.
Source of Article