LC Labs Letter: December 2021
December 2021
LC LABS LETTER
A Monthly Roundup of News and Thoughts from the Library of Congress Labs Team
LC Labs Experiments
Humans in the Loop experiment pairs machine learning and human expertise
Starting in 2020, our team collaborated with data solutions provider AVP to prototype workflows combining machine learning and crowdsourcing. Our previous work on machine learning taught us that fine-tuned training data for historical content is important and rare. The reports we’ve commissioned and worked on also emphasize that human decision-making is at the heart of any machine learning process; so is the potential for risk and biases introduced by these human elements.
The latest Humans in the Loop initiative researched and prototyped workflows for ethically, engagingly, and usefully combining crowdsourcing tasks to inform machine learning processes and vice versa.The result is a four-stage framework for designing ethical and impactful human-in-the-loop approaches.
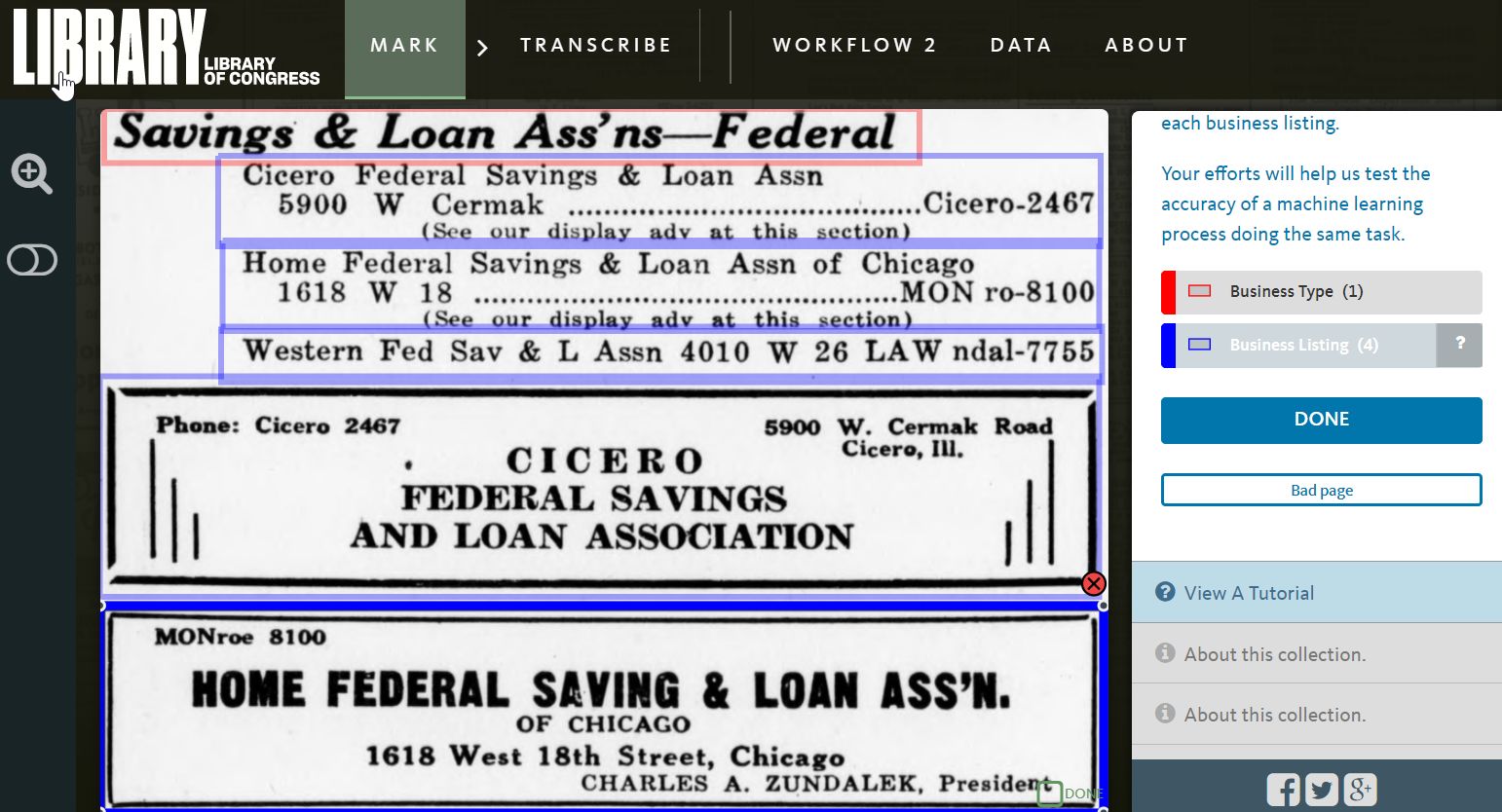
Screenshot of a prototype interface for segmenting a business listing from the U.S. Telephone Directories Yellow Pages. The resulting data was used to train a machine learning algorithm to successfully identify other visually similar content.
The outcomes of the experiment reveal that human in the loop approaches have potential to be extremely powerful for maximizing access to LC’s content at scale but that they will require significant investment in staffing and resources. The experiment also notably concluded that there will not be a one-size-fits-all approach to humans in the loop workflows.
The Humans in the Loop Recommendations Report also points to three key areas for further research in the field: sharing data generated by HITL workflows, increasing diversity among teams, and iteratively conducting user testing while developing crowdsourcing and end-user platforms for collection engagement. Download the report for more information, or check out the experiment page.
Recent blog post explores how teachers might use Library of Congress datasets
Since 2020, the Library of Congress has been acquiring datasets as part of the Selected Datasets collection. LC Labs staff have been working closely with Einstein Distinguished Educator Fellow Peter DeCraene to examine if, and how, a high school computer science teacher like Peter could incorporate datasets from this collection in their lessons.
In a recent blog post on the Signal, Peter and Eileen explain how they made a large database from the collection more suitable for classroom use by creating a derivative dataset. The blog post details how they decided what dataset to work with and raises some questions about how to describe a derivative dataset that is closely related to, and yet distinct from, the primary source.
Please continue to engage with us in the blog post’s comments section about this complex yet engaging topic!
See Speculative Annotation in action
Watch a demonstration of the Speculative Annotation web application created for the Library of Congress by artist and 2021 Innovator in Residence Courtney McClellan. To learn more about the Speculative Annotation experiment, read our final interview with McClellan on The Signal.
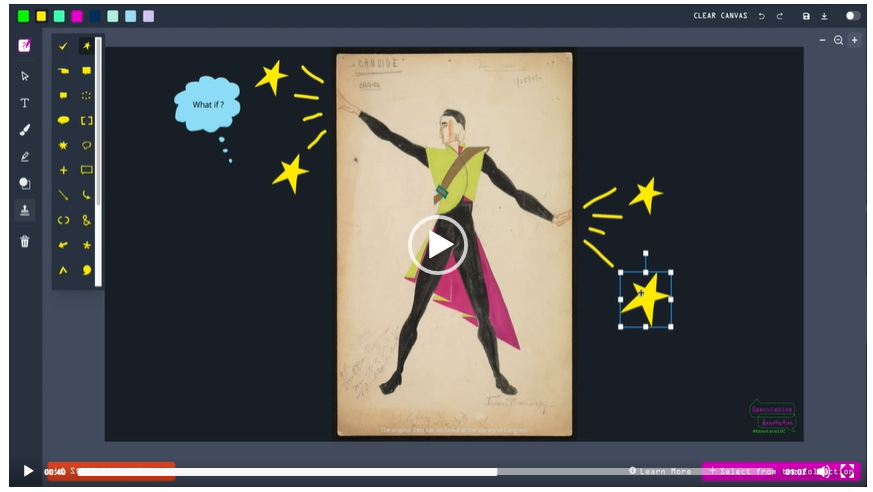
Demonstration video of the Speculative Annotation tool available at: //www.loc.gov/item/webcast-10116/
To subscribe to the monthly LC Labs Letter, visit //updates.loc.gov/accounts/USLOC/subscriber/new?topic_id=USLOC_182
For more information about LC Labs, visit us at https://labs.loc.gov/
Questions? Contact LC Labs at [email protected]
Source of Article