Innovator Ben Lee and LC Labs Host “Data Jam” with 100 Million Historic Newspaper Images

A gallery of historic moustaches, a wall of 12,000 photos, a collage of First World War-era “damn the Kaiser” cartoons, and more were on display May 7, when 135 people attended a virtual “data jam” to dig into a massive new collection of historic newspaper images. LC Labs hosted the event to showcase Library of Congress Innovator in Residence Ben Lee’s work extracting visual content from the Chronicling America digital newspaper collection. After a behind-the-scenes look at Lee’s project, Newspaper Navigator, “jammers” had the chance to work with the images themselves for the first time.

A “gallery of moustaches” created by Newspaper Navigator data jam participant Mary Feeney
The Chronicling America Historic American Newspapers site currently holds over 16 million pages of newspapers. Researchers, family historians, and the curious have long sought its images, including photographs, maps, cartoons, and ads. Until recently, however, the only way to collect that visual content was to comb through page after page of text—a project that would take decades. Last week’s event showcased a solution that uses computing power and new machine learning techniques to do that work in days.
Framing his research, Lee said last week, was this question: “Can we throw open the treasure chest of Chronicling America by training a machine learning algorithm to process all of Chronicling America?”

A collection of images created by Newspaper Navigator data jam participant Brian Foo
During his introduction to the new collection, Lee explained that his work was made possible by a paradigm shift in machine learning techniques. Instead of training models from scratch, machine learning practitioners now use community datasets to pre-train their models, such as the Common Objects in Context (COCO) dataset, and then fine tune with smaller datasets – in this case, annotations resulting from the Beyond Words crowdsourcing initiative, along with some additional annotations. This method streamlines and expedites the process of creating and training models, while allowing for fine tuning—for example, ensuring that models are able to sort out how to differentiate photographs from illustrations on newspaper pages.
Lee was able to process 16,368,041 pages of newspaper text—99.998% of the Chronicling America collection, which includes nearly two centuries of historic newspapers contributed by 48 states and territories. Using 96 CPU cores and 8 GPUs, the process took only 19 days, harnessing years of compute time as efficiently as possible. You can learn more about Lee’s model, training set, and the pipeline in The Newspaper Navigator Dataset: Extracting and Analyzing Visual Content from 16 Million Historic Newspaper Pages in Chronicling America and GitHub repo.
What did he find? An astounding 100 million photographs, illustrations, maps, comics, editorial cartoons, headlines, and advertisements.
All of those images are now available for download on news-navigator.labs.loc.gov. There, you can also find prepackaged files sorted by year and by type (photos, comics, etc.). The prepackaged image sets are available in zip files, with metadata in JSON and CSV (spreadsheet-friendly) formats. Smaller “sample packs,” designed for quick download, contain 1,000 random images of one type for the year.
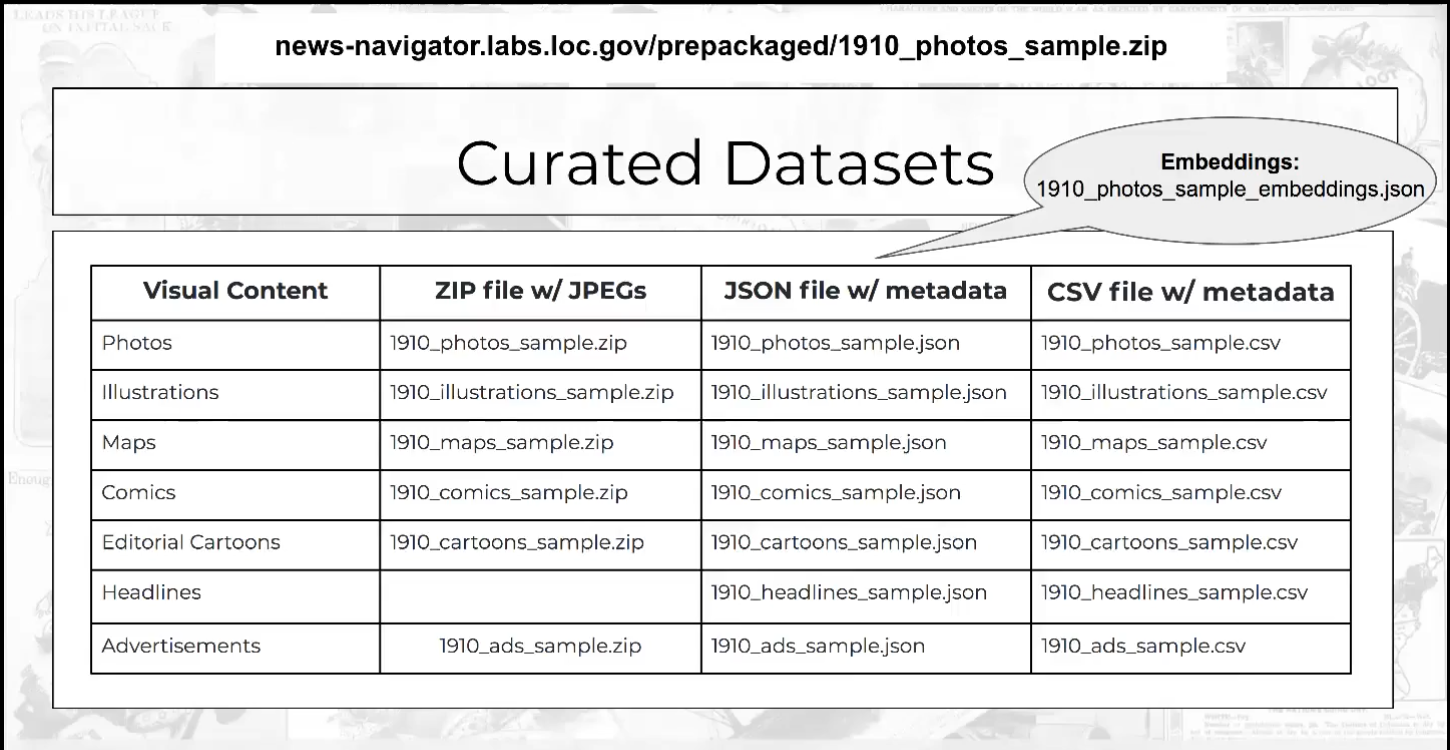
Innovator in Residence Ben Lee’s list of curated datasets of images from Chronicling America
The data jam invited people from all over the world to view and use these free images, which are all in the public domain. Lee and the Library envision everything from collages to large-scale computing projects on the images. “We want to see an active public conversation” about these images and what people are doing with them, said Senior Innovation Specialist Jaime Mears, who coordinates the Innovator in Residence program.
Aside from their sheer number, why are the images in Chronicling America so intriguing? Deb Thomas, manager of the program, explained that newspapers were the main form of communication in the 19th and 20th centuries, the source that people looked to first. Nearly every town and community in the United States began publishing its own newspaper, providing a remarkable record of the things people knew at the time—“history as it happened,” so to speak. Chronicling America and the National Digital Newspaper Program are a partnership between the Library and the National Endowment for the Humanities since 2005, building on a decades-long effort to find and preserve America’s historic newspapers on microfilm. In 2010, the Library made Chronicling America’s data open to all.

A “D–n the Kaiser” cartoon from a collection assembled by data jam participant Jeremy Guillette using Newspaper Navigator
After Lee, Thomas, and Mears spoke about the project, data jammers were ready to dig in and see what they could find and create. They showed off visualizations, collages, queries—and even a few challenges. Some of them are found in the images here, and you can follow the #NewspaperNavigator hashtag on Twitter to see more. A public user interface for the data will be available in late summer, so stay tuned!

Collage created by data jam participant and LC Labs Senior Innovation Specialist Meghan Ferriter using images found by Newspaper Navigator
Missed the data jam this time around? You can download the images at news-navigator.labs.loc.gov. And if you do create something interesting, we’d love to see it! Email us or tweet @LC_Labs using the #NewspaperNavigator hashtag. We can’t wait to see what you find!
Source of Article