Happy Birthday to LCWA! Celebrating the 20th Anniversary of Web Archiving at the Library of Congress.
Today’s guest post is from Abbie Grotke, who is Lead Librarian, Web Archiving Team in the Digital Content Management Section of the Library of Congress.
2020 marks a special occasion for the Library of Congress – our anniversary of 20 years of web archiving!
Remember the year 2000? Back when we all breathed a collective sigh of relief that our systems didn’t crash thanks to Y2K? I remember it well, partly because I was working in nearly the same office (well, not currently, since I’m working from home right now). I was in my early years at the Library of Congress, transitioning from digitization projects to other types of digital library work. Little did I know that there was an activity brewing in another part of the Library that would ultimately change the course of my career when I joined the project team a few years later.
Figure 1. MINERVA: Mapping the Internet Electronic Resources Virtual Archive.
It was in 2000 that the Library of Congress embarked on a web preservation pilot project, which eventually became the Library’s web archiving program. An acronym to describe the pilot program was born to align with a beautiful mosaic in the Jefferson Building: “MINERVA: Mapping the Internet Electronic Resources Virtual Archive” (you can see an early capture in figure 1.) From our records, the pilot program activities began around this time in 2000, and after some early test crawls, the first collection, related to the Election 2000, began in August 2000. Like many national libraries, election archives were a natural first archive, since many campaign websites tend to disappear.
The early pilot efforts (figure 2)were well documented in two reports written in 2001 by project consultant William Arms, who at the time was at Cornell University: an interim report issued in January and a final report in September. The reports reflected the project team’s experiences, outlined progress and outcomes of the pilot, and included recommendations for the Library to consider as it embarked on collecting this new form of content. The reports go into detail about topics familiar to us seasoned and just-getting-started web archivists: selection and collection policies, potential uses for scholarship and research, information discovery, discussions of copyright and legal issues, long-term preservation, and suggestions regarding the development of a production system to accomplish the work.

Figure 2. Early capture of the Web Preservation Project Pilot.
Digging around for links in our archive to the reports, I was also reminded of some articles describing the early efforts that were posted on an early version of our website: “Election 2000, as It Happened: Library and Alexa Announce Election Web Archives” from the Library of Congress Information Bulletin (July –August 2001). This RLG News article was written by Arms and members of the pilot team: “Collecting and Preserving the Web: The Minerva Prototype” (bonus: you can see evidence of our inability to get all of the images in those early days.) This presentation (downloadable PPT file) about the pilot is also fun to flip through given what we know now in 2020.
We have packed a lot to be proud of into the past 20 years. While we were hoping to have a big event and party this spring to celebrate (that is on hold for obvious reasons), so we are moving to virtual celebration of the program for now. Stay tuned on the Signal for highlights, stories, and people that were involved in the early years of the program, and some of the accomplishments in our first 20 years. We’ll also be on Twitter — look for special #WebArchiveWednesday tweets on @librarycongress and @LC_Labs that will feature content and tales from the archive.
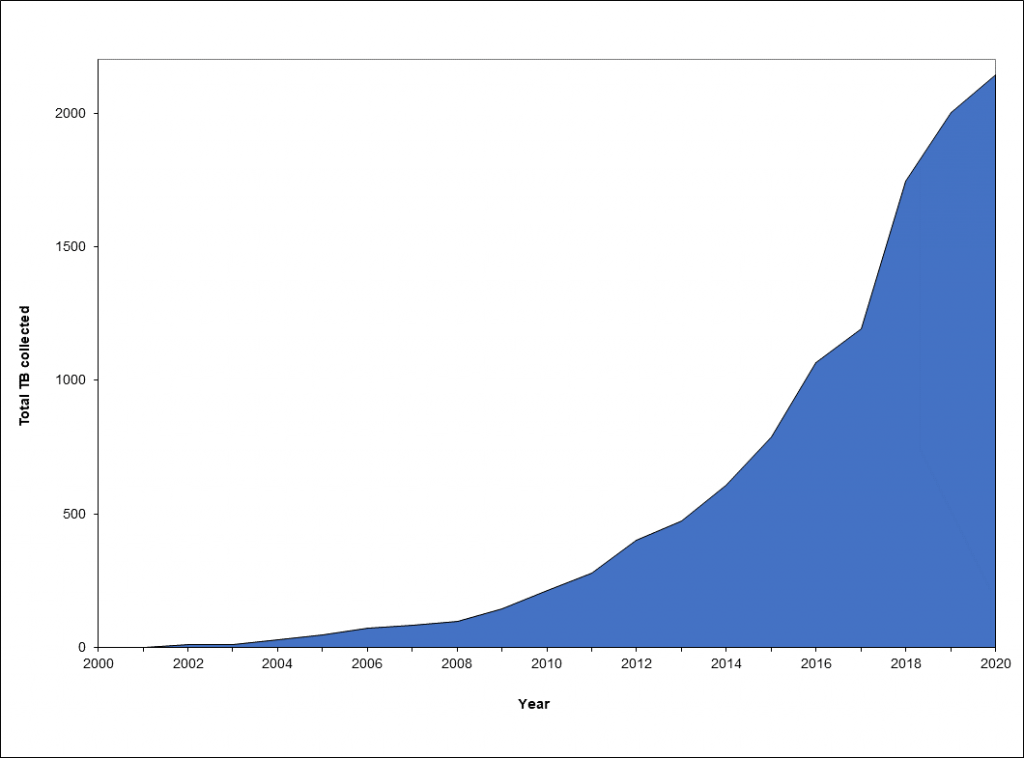
Figure 3. Over the last 20 years, web archiving has grown dramatically, you can see how the program has grown to more than 2000 TB or over 2 Petabytes of data.
Source of Article