Experimenting with speech-to-text and collections at the Library
This guest blog post is shared by Chris Adams, Solutions Architect in the Office of the Chief Information Officer/IT Design & Development Directorate, and Julia Kim, Digital Projects Coordinator at the National Library for the Blind and Print Disabled at the Library of Congress, formerly the Digital Assets Specialist at the American Folklife Center, supporting digitized and digital multi-format content for digital preservation and access workflows. In this post, they share more about exploring the feasibility of off-the-shelf tools to enhance description and aid in processing of Library of Congress collections. Read on for more background on the phases of the Speech-to-Text-Viewer experiment from creating the viewer interface to exploring its utility in processing workflows.
Speech-to-text transcription software is technology that transcribes audio recordings into text automatically. That text data can then be read by people and processed by machines, which helps to facilitate search and discovery of the content of sound recordings.
Recently, we collaborated with other staff members from the Library of Congress, including LC Labs, on an experiment to test the feasibility of using an out-of-the-box speech-to-text solution on digital spoken-word collections from the American Folklife Center (AFC). This experiment was possible through the collaboration of staff from different disciplines at the Library, working on experimental prototypes with a broad range of collections. We hope that our work has not only increased our own organization’s familiarity with the implementation of speech-to-text tools, but also contribute to a broader collective knowledge by providing access to our code repositories, readme files, conference presentations, and, of course, blog posts.
The use of speech-to-text software does not eliminate the need for human intervention, but it significantly lessens the work needed to make recordings accessible. Archivists and software developers have teamed up in recent years to build tools that make processing these materials more feasible. Some uses of speech-to-text applications in archives include work built off of Pop Up Archive with WGBH’s use of the Kaldi speech to text tool, the Studs Terkel Radio Archive; the Ohms – the AVP AVIARY project, which builds on the indexing work from the Nunn Center for Oral History and OHMS; and Stanford’s long running ePADD email processing project.
This work, however, is far from easy, due to the quality of audio made on various recorders, “noise” introduced as tapes and other media age, and different English dialects and non-English languages. All of these challenges are considerations when building software to automate the conversion of audio recordings into text.
Transcribing and Viewing
In order to begin exploring this technology, we worked with LC Labs to test the Amazon Transcribe service. The existing LC Labs infrastructure and team made it possible to quickly conduct a basic test using some of the already public collections.

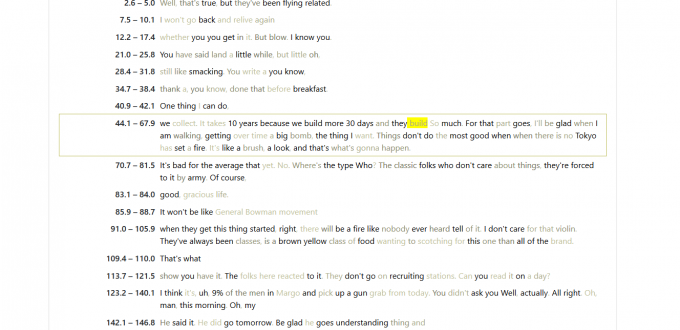
Speech-to-Text Viewer example file from an older, low-quality audio recording from the “Man on the Street” presentation
Since reviewing the results requires easy comparison between the audio files and the resultant transcribed text, we built what we call the “Speech-to-Text Viewer.” This viewer makes it easy to review large numbers of files, get a visual overview of the reported confidence levels, and skip to any point in time in the transcript and corresponding audio. The viewer was designed to allow for the possibility of adding other services and potentially allow reviewers to save their results for feedback.
We’re happy to share that the Speech-to-Text Viewer will be available to the public for a limited time, as an experiment hosted by LC Labs. We hope that sharing this proof of concept will help other instantiations, and our own, better understand their requirements in this space and potential solutions. Files publicly available through Viewer are from the following AFC online presentations and collections: Florida Folklife afc1941004 (Man on the Street Interviews), afccal000001 (Center for Applied Linguistics), ncr002361 (Buckaroos in Paradise), qlt000001 (Quilts and Quiltmaking), afc1981005 (Montana Folklife), afc1982010 (South-Central Georgia Folklife), cmns000620 (Coal River Folklife), afc911000265 (September 11th, 2001), afc2010039, afc2012003 (Big Top Show Goes On), afc2016655443 (Port of Houston)
The Speech-to-Text Viewer provides a display which offers a searchable list of items from an index and allows you to select one for synced transcription playback. Users can follow along with a transcription of audio content, such as interviews, or other spoken word, as they’re listening in real time along with the transcription’s self-assessed accuracy from 0 – 100%.
(left to right) 1. The public Speech-to-Text Result Viewer Gitlhub, 2. View of speech to text application components
Outcomes of the experiment
In our experiment, the transcriptions’ self-assessed confidence ratings varied significantly based on the source material and sometimes were highly inaccurate because many of the test audio collections contained regional and older styles of speech, which we hypothesize were not used in the training sets. These issues are inherent to some collections; even listening and understanding what is being said can be very difficult. Additionally, many items had gone through previous necessary physical carrier migrations before being digitizing, resulting in what audio people call poor “signal-to-noise” ratios, with artifacts like crackling. The accuracy of contemporaneous born-digital audio, in contrast, was high.
The experiment, as we’d hoped, raised many questions and topics for further study, including how to implement a text-to-speech service in a way that doesn’t bias English-language spoken word and styles of speech contemporary, mainstream technology is trained on. This project also spurred interesting conversations on what are “good enough” thresholds? The Library (and other institutions) has wrestled with this question beginning with early digitization and OCR workflows. And how do these thresholds relate to (web) accessibility concerns and requirements supporting dis/abled users?
The experiment has been great for fostering robust and ongoing discussion in these areas and more. Please email [email protected] with any feedback on the tool or existing documentation.
Source of Article