Computing Cultural Heritage in the Cloud Quarterly Update

This is a guest post from LC Labs Senior Innovation Specialist Laurie Allen. This is the second post in a series where we are sharing experiences from the Andrew W. Mellon-funded Computing Cultural Heritage in the Cloud. The series began with an introductory post. Learn about the grant on the experiments page, and see the press release here.
We are currently hiring for the Digital Scholarship Specialists!! Applications due by January 30!
In the introductory post, I described the background and the ways that the cloud-based model offered in the grant is related to current library services and infrastructure. In this post, I’ll lay out the planned activities in the grant, and the progress to date. This post roughly follows the slides from the December 13 update call.
The next update call will take place on March 17 at 1pm via webex. Let us know your questions ahead of time by filling out this form.
First, we are extraordinarily fortunate to have an incredible advisory board on this project. They have already helped shape our understanding of the project in important ways, and provided guidance on some decisions In alphabetical order by last name, they are: Harriet Green, an Associate University Librarian at Washington University in St Louis, who brings years of Digital Scholarship leadership in academic libraries, as well as teaching to work with text mining, and developing creative publishing models for digital scholarship; Dr. John Hessler, from our own Geography and Maps division does cutting-edge work in computationally analyzing maps, among many other things; Katrine Hofmann Gasser from the Royal Danish Library, who provides great guidance from another national library perspective and models deep partnerships in digital scholarship support; Dr. Liz Lorang, who is not only an expert on creative uses of machine learning, but has considerable experience working computationally with collections at the Library of Congress; Dr. Sarah Stone from the eScience Institute, who has already helped us think through models to support data science collaborations to address big research questions; Dr. Ian Milligan, a historian who is leading the use of web archives in historical research on the recent past; Dr. Safiya Umoja Noble who is internationally known for her work exploring bias in search algorithms and critically engaging with the information landscape; and Dr. John Walsh who directs the HathiTrust Research Center, which is at the forefront of computational approaches to textual data from libraries. This group of experts forms our advisory board, and we are looking forward to drawing on their knowledge and perspectives throughout the project.
As mentioned in my last post, this grant is designed to help with a relatively simple problem. The Library gets requests for custom slices of our data that we are currently unable to provide. Sometimes, people want bulk access to a single collection in a form that we currently do not offer while in other cases, they want to run computing processes against data that crosses collection and format boundaries. These custom slices would be difficult and expensive to provide in our current environment, and the Library needs more information about cost models, potential benefits, and potential harmful outcomes of any proposed service before we invest resources in it. So, the Computing Cultural Heritage in the Cloud project is designed to help us determine the kinds of supports (technical, infrastructural, and interpersonal) that our readers and researchers need to use digital collections data at scale. It will help us test financial models for enabling users to do data reduction in a distributed data environment, and will hopefully lead us closer to a future in which we can provide broader access to Library materials.
In order to help the Library learn as much as possible about any potential service or infrastructure models, Computing Cultural Heritage in the Cloud funds will support four research experiments working for 9 months, two full-time digital scholarship specialists, and a project documenter for the length of the project. We are aiming for a diverse group of researchers or research teams to undertake these four research experiments – people who have their own scholarly, practical and technical questions that require computational uses of library collections.
By funding and supporting these four experiments, and documenting the work, we will learn about the computing environment, process, quality of data availability, processing tools, and delivery mechanisms needed for specific forms of research. The researchers awarded funds for their experiments will be invited to use library collections in the dedicated cloud environment, will have support from the digital scholarship experts (see below for information about the call), and will have resources to support computing against those library collections.
As of winter, 2019/2020, we have mostly so far been preparing the position descriptions for the digital scholarship specialists, drafting the call for research experts, and gathering possible collections for computational research. So far so good on all three fronts!
The posting for digital scholarship specialist is available online now; the call for research experts will likely be issued as a Broad Agency Announcement this spring; and I’m learning a lot about collections.
Identifying and preparing collections for the cloud
The Library of Congress is the largest digital library in the world, with millions of digitized items across a huge range of formats (books, films, photographs and prints, sound recordings, etc) as well as petabytes of collections that have always been digital (most notably a huge collection of web archives). However, not all of these collections can or should be made available for computational uses in a cloud environment. There are technical, legal, and ethical reasons why some collections are not available online, or, in some cases, where collections that have been approved for viewing online at loc.gov may not be appropriate for computational uses. In order to identify collections that will lend themselves to computation, as well as the set of considerations to consider, I’ve so far found that the best option is meetings. In settings both formal and informal, I’ve been learning from my colleagues about the collections.

Credit Fleischhauer, Carl. Community meeting, Tifton, Georgia. Georgia Tifton United States, 1977. Tifton, Georgia. Photograph. //www.loc.gov/item/afc1982010_cf_106/

Fleischhauer, Carl. Community meeting, Tifton, Georgia. Georgia Tifton United States, 1977. Tifton, Georgia. Photograph. //www.loc.gov/item/afc1982010_cf_105/.

United States Resettlement Administration, Shahn, Ben, photographer. Religious meeting, Nashville, Tennessee. Nashville Nashville. Tennessee United States, 1935. Sept. Photograph. https:// www.loc.gov/item/2017730295/.
Through these meetings with colleagues in LC Labs as well as across the library–that I hope were much more lively and cheerful than the meetings pictured above in the Library of Congress collections– we’ve identified three categories of collections that we can prioritize for making available computationally, including 1) the low-hanging fruit (i.e. the materials already available on LC for Robots 2) collections data that is non-rights restricted, or where the rights are extremely clear 3) collections with big potential, according to past uses, or curator knowledge. Examples of possibilities that fall into that third category are: the digitized Sanborn maps ; the collection of telephone directories ; Chinese rare books; or digitized stereographs among so many others.
In an effort to imagine how researchers will find their way to good computational uses of collections, I am trying to develop a “Collection cover sheet” or “readme.” This effort draws on lessons from other collections as data projects, most notably a project I contributed to from 2015-2018, the IMLS funded Always Already Computational https://osf.io/mx6uk/wiki/home/. During that project, we consistently heard how the metadata that libraries make available to help readers understand a particular item is not always the same information that researchers need when they are seeking to use collections with computational methods. For computational uses especially, researchers want to understand the structure of the collection at multiple levels, as well as its provenance – where it came from and how it has been transformed, as well as what is missing from the data, and what kinds of uses are allowed with it. The collection cover sheet template below is an attempt to gather that information for collections that might become part of this cloud environment. Of course, it is in early development and will likely change (or may become superfluous) as the project continues.

Proposed template for a “collection cover sheet.”
Project Timeline
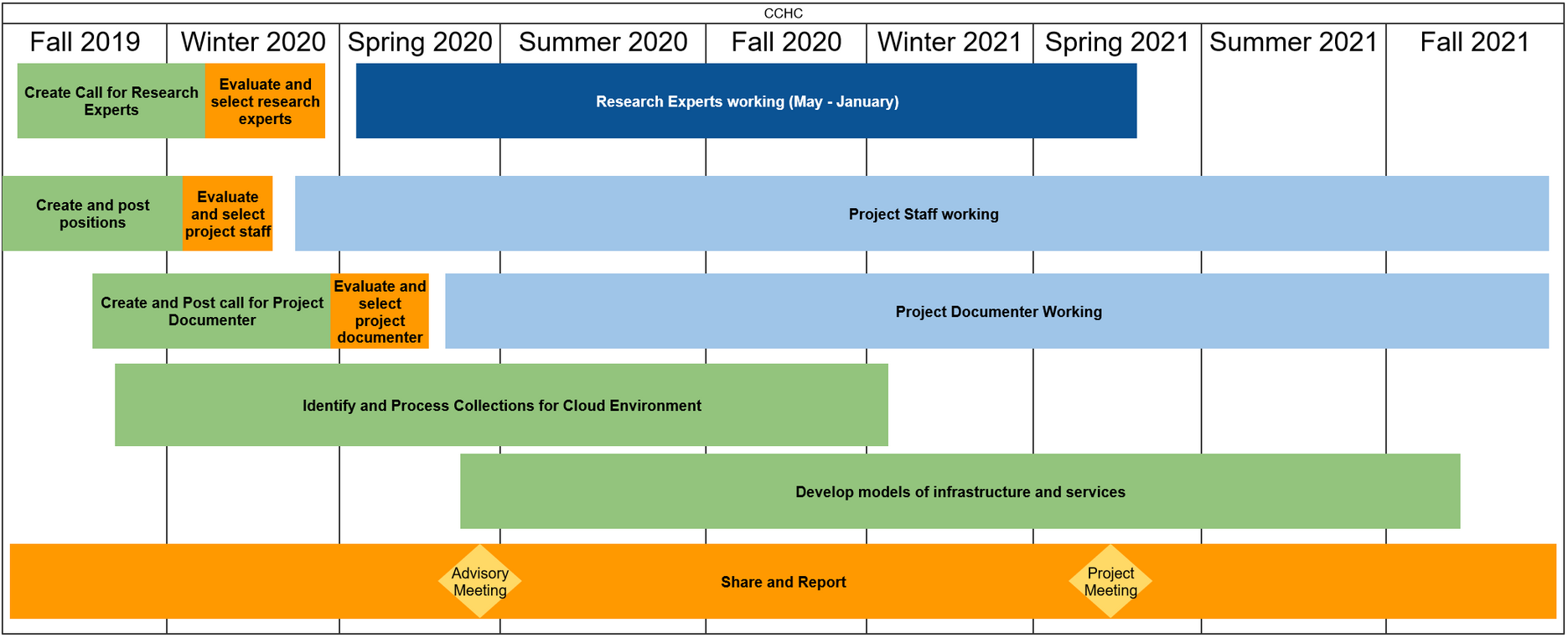
Proposed CCHC project timeline
In the coming months, keep an eye out for the call for research experiments, and please do consider applying for the fantastic learning opportunity presented by these positions.
By inviting two full-time digital scholarship specialists to join the LC Labs team specifically to work on this project including well after the researchers have finished their projects, we hope to learn together with these specialists about how the library can provide this new service. These specialists will bring some library skills and some technical skills to the project, and will learn with us as we all discover what kinds of services and infrastructure make most sense for the Library to consider implementing going forward.
Source of Article